Asset management

IS NOW THE TIME FOR MACHINE LEARNING?
EITAN VESELY, PRESENSO, HAIFA, ISRAEL
AS CAPITAL EXPENDITURES and O&M budgets are cut in response to the precipitous fall in worldwide petroleum prices, there is growing interest in the unrealized economic potential of Industrial Analytics. Shrewd marketing on the part of certain vendors has created a perception that machine learning is the holy grail solution for increased uptime and higher recovery rates.

Let's start with the bullish forecasts. McKinsey Consulting estimates that the potential economic benefit of using advanced analytics is a 13% reduction in maintenance costs. According to GE, companies using predictive, data-based approach experience 36% less unplanned downtime and can save an average of $17 million per year. Not to be outdone, Cisco goes even further by audaciously claiming that industry-wide adoption of IoT can grow GDP by 0.8%.
Not surprisingly, these organizations do not share their underlying assumptions and calculations.
This article provides a realistic assessment of the alternatives for Machine Learning for Predictive Maintenance in the oil and gas industry based the near-term outlook for O&M, infrastructure investment, and workforce dynamics.
CURRENT STATE OF OVERALL EQUIPMENT EFFECTIVENSS (OEE)
From an operational perspective, the most important metric to consider is Overall Equipment Effectiveness or OEE. The OEE measurement includes availability (uptime), performance (speed), and quality of output (defect rate). It is calculated as follows: OEE = Availability * Performance * Quality (see Figure 1).

How does the oil and gas industry rate? According to the Aberdeen Group, the average oil and gas company has an OEE of 73%. This compares to the best in class of 89%. One of the largest contributing factors is unscheduled downtime. Between 2009 and 2012, there were more than 1,700 refinery shutdowns in the US. This is an average of 1.16 shutdowns a day. Significantly, more than 90% of the maintenance-related shutdowns were unplanned.
The economic impact is well documented. The average daily cost of unscheduled downtime is $7 million for an onshore well and substantially more for offshore facilities.
Furthermore, the outlook for OEE is getting worse. Since the fall in oil prices, there has been a significant reduction in both new capital expenditures and O&M investment. In periods of instability, deep budget cuts can be random and asset maintenance has become less of a priority. The expected result is further deterioration in medium- to long-term asset performance.
THE SHIFT TO INDUSTRIAL IOT IN THE ERA OF LOWER PETROLEUM PRICES
The emergence of Industry 4.0 has coincided with the industry downturn. Executives have taken note and at a strategic level there has been a shift from maximizing revenue to optimizing production. Last year, Microsoft and Accenture commissioned a study called the "Upstream Oil and Gas Digital Trend Survey." The main findings: even with the reduction in commodity pricing, executives are committed to digitalization and recognize the value in industrial analytics. In fact, 66% of respondents believe that analytics can transform their business. There is a strategic understanding of both the cost benefit and the improvement in productivity that can be gained by digital technologies. Finally, 56% of respondents stated that they intend to use the cloud to enable analytical capabilities within the next three to five years.
THREE APPROACHES TO MACHINE LEARNING FOR ASSET MAINTENANCE
It's easy to be overwhelmed by the hype surrounding Big Data, Machine Learning, and Industrial Analytics. The notion is simple: using sensor data to predict machine failure. At the same time, there is no clear path to implementation. Below we outline three approaches to Machine Learning for Asset Maintenance and assess their practicality.
MANUAL STATISTICAL MODELING
The most basic approach to Machine Learning is to create an internal group within an organization that can generate predictive models. Sample data is taken from machines and then data scientists build statistical models. The data scientists extrapolate from the sample data to the specific machines.
Having worked in this industry and also spoken with several industry executives, I know the challenges they face building internal competencies in Machine Learning. First, there is a worldwide shortage of big data scientists and engineers. As the industry faces margin pressure and copes with an aging workforce, it is unrealistic to recruit a critical mass of highly skilled big data professionals into an organization focused on production. The industry will also struggle to compete with the compensation levels that are provided in the financial services and high-tech sectors which is attracting many of the big data professionals. This approach may be limited only to a few industry giants.
The alternative to creating an internal Data Science Center of Excellence is the cheap-and-dirty citizen data scientist concept. A couple of years ago, Gartner coined the term "citizen data scientist" to refer to an individual who "generates models that use advanced diagnostic analytics or predictive and prescriptive capabilities, but whose primary job function is outside the field of statistics and analytics."
Underlying the concept of the citizen data scientist is that off-the-shelf analytics tools would democratize the field of statistics. The reality is more complex. Statistical models become obsolete quickly. No matter how robust a software package, the decision about which statistical model or algorithm to use cannot be made by a technician.
In other words, building internal capabilities is a resource intense commitment that will require additional headcount and budget.
SIMULATED MODELING
The Digital Twin concept has gained much attention and has been highlighted by Gartner as a leading IT trend for 2017.
It is a simple concept to understand, but is complex (and expensive) to implement. At a high-level, it works as follows: a virtual clone of a machine asset is created using the blueprints of the physical machine. his requires an army of data scientists, design technicians, and other subject matter experts. The Digital Twin uses the so-called Supervised Machine Learning methodology, which requires the virtual machine to "learn" the underlying asset behavior before it can detect performance abnormalities. To work effectively, the Digital Twin needs to be an exact replica and there can be no deviations between the physical and virtual asset.
Figure 2 depicts the iterative nature of how the Digital Twin is deployed.
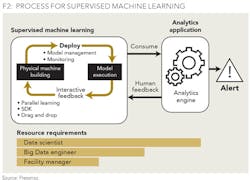
PROCESS FOR SUPERVISED MACHINE LEARNING
With its Predix offering, GE has positioned itself as a top vendor in this category. Other players include SAP and Siemens. Each Digital Twin is created and customized for a unique asset and not for an entire upstream oil platform or downstream refinery.
Although the Digital Twin is a remarkable technology, oil and gas companies struggle with its deployment for the following two reasons:
Industry infrastructure is aging and the outlook for asset performance is troubling. More than 50% of worldwide oil production is from machinery that is beyond midpoint in the asset lifecycle. Why is this important? To create the Digital Twin, technicians use the actual asset blueprint which often deviates from the underlying asset. That is because over time, as machines are repaired and upgraded, there are changes that are not always captured. Creating a Digital Twin with aging assets is a time consuming, expensive, and laborious task.
Oil and gas companies face an impending labor shortage because of an aging working. According to Mercer Management's "Oil and Gas Talent Outlook 2016-2025," 20% of geoscientists in Europe and 23% of petroleum engineers will reach retirement age by 2020 in the US and Canada. What is often not recognized about the Digital Twin is that it requires the input of facility engineers and technicians. The Machine Learning does not happen automatically and the Digital Twin needs to precisely model the underlying asset. Given cuts to O&M budgets and an overall talent shortage in the industry, the ability to assign existing facility staff to create the Digital Twin is a major challenge.
Finally, it should also be noted that the Digital Twin is built on a per-asset basis. In other words, a Digital Twin is not created for an entire rig or refinery. Rather, it can be created for specific machinery or assets. The issue of scalability and cost effectiveness is a major drawback given current levels of commodity pricing. It may be conceivable that GE provides airplane producers with a Digital Twin model for each new and expensive jet engine GE sells them, but most of the market in oil and gas is brownfield.
UNSUPERVISED MACHINE LEARNING
An alternative approach to Simulated Modeling is Industrial Analytics based on Unsupervised Machine Learning.
Let's go back to the Digital Twin. The Digital Twin technology is based on the so-called Supervised Machine Learning methodology. It "trains" the algorithm on the underlying asset by providing it with data labels or classifications. When Machine Learning that is supervised recognizes new data, it then associates it with the data labels that it has already learned.
With Unsupervised Machine Learning, data labels are not provided to the algorithm. Instead, vast amounts of data are analyzed and the algorithm itself generates the labels.
The algorithm is looking for abnormal sensor or signal behavior. Once it detects anomalies the data, correlations, and pattern detections between signals are performed. This is done to later present the operators with the exact sequence of abnormal events detected. Once an evolving failure has been detected, a failure alert is generated. This alert includes information on correlated sensor abnormalities. This valuable information significantly helps in tracking the failure origin.
Apart from methodology, the key difference between Simulated Modeling and Unsupervised Machine Learning is how it is applied to a production facility. With the Digital Twin, a unique clone is created for every asset. With Unsupervised Machine Learning, the algorithm is agnostic with respect to sensor or asset type. The algorithm is trained to find anomalous sensor behavior (or patterns of anomalous behavior) and to use this information to provide early warnings of machine degradation or asset failure.
Significantly, Unsupervised Machine Learning can be applied to all the assets in rig or refinery. In other words, whereas the Digital Twin needs to "learn" each asset separately, Unsupervised Machine Learning is analyzing data and looking for patterns. It is agnostic with respect to sensor or asset type and can be used by an entire production facility.
CONCLUSION: CAVEAT EMPTOR
This article summarizes the three major approaches to Industrial Analytics and Machine Learning for Asset Maintenance. Given commodity prices and the current state of assets in the oil and gas industry, a conservative model for investment in this type of solution is necessary.
We are not suggesting that you delay implementing a Machine Learning for Asset Maintenance solution. Instead, we recommend a conservative, fact-based approach:
• When creating the business case for Industrial Analytics, test each solution provider by giving them with two to three years of historical data. Compare their predictions of machine failure relative to actual failures.
• Include two to five solution-providers in the test.
• For final vendor selection and to forecast ROI and TCO, use data that is based on the pilot instead of relying on industry benchmarks.
There is an almost universal consensus about the vast economic potential for Machine Learning for Asset Maintenance in the oil and gas industry. Our recommendation is to approach solution and vendor selection using a data-driven methodology to maximize the likelihood of success.
ABOUT THE AUTHOR

Eitan Vesely is the CEO of Presenso. He was previously a hardware specialist and a support engineer for Applied Materials where he specialized in software-hardware-mechanics interfaces and system overview. He holds a bachelor of science degree in mechanical engineering.